1 Presentation
This is the analysis code for the paper “Changes in the Justification of Pension Inequality in Chile (2016–2023) and its Relationship to Social Class and Beliefs in Meritocracy”. The dataset used is df_study1_long_t7.RData.
2 Libraries
3 Data
Show the code
load(file = here("input/data/proc/df_study1_long_t7.RData"))
glimpse(df_study1_long_t7)Rows: 16,356
Columns: 17
$ idencuesta <dbl> 1101011, 1101012, 1101021, 1101023, 1101032, 110…
$ muestra <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
$ ola <fct> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
$ ponderador_long_total <dbl> 0.11821742, 0.11821742, 0.05633656, 0.07703080, …
$ segmento <dbl> 110101, 110101, 110102, 110102, 110103, 110103, …
$ estrato <dbl> 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, …
$ just_pension <fct> Strongly disagree, Disagree, Neither agree nor d…
$ egp <fct> NA, NA, Working class (V+VI+VII), Intermediate c…
$ merit_effort <fct> Agree, Agree, Agree, Neither agree nor disagree,…
$ merit_talent <fct> Agree, Agree, Agree, Strongly agree, Strongly di…
$ educ <fct> Less than Universitary, Less than Universitary, …
$ educyear <dbl> 4.30, 9.80, 14.90, 9.80, 12.02, 13.90, 12.02, 7.…
$ sex <fct> Female, Female, Male, Male, Female, Female, Male…
$ age <dbl> 64, 60, 51, 62, 54, 32, 38, 69, 56, 65, 35, 26, …
$ aget <fct> 50-64, 50-64, 50-64, 50-64, 50-64, 30-49, 30-49,…
$ ideo <fct> Does not identify, Does not identify, Does not i…
$ n_participaciones <int> 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, …Show the code
# Generate analytical sample
df_study1 <- df_study1_long_t7 %>%
select(-muestra) %>%
na.omit() %>%
mutate(ola = case_when(ola == 1 ~ 1,
ola == 2 ~ 2,
ola == 3 ~ 3,
ola == 4 ~ 4,
ola == 6 ~ 5,
ola == 7 ~ 6)) %>%
mutate(ola = as.factor(ola),
ola_num = as.numeric(ola),
ola_2=as.numeric(ola)^2)
df_study1 <- df_study1 %>%
group_by(idencuesta) %>% # Agrupar por el identificador del participante
mutate(n_participaciones = n()) %>% # Contar el número de filas (participaciones) por participante
ungroup()
df_study1 <- df_study1 %>% filter(n_participaciones>1)
# Corregir etiquetas
df_study1$just_pension <- sjlabelled::set_label(df_study1$just_pension,
label = "Pension distributive justice")
df_study1$egp <- sjlabelled::set_label(df_study1$egp,
label = "Social class")
df_study1$merit_effort <- sjlabelled::set_label(df_study1$merit_effort,
label = "People are rewarded for their efforts")
df_study1$merit_talent <- sjlabelled::set_label(df_study1$merit_talent,
label = "People are rewarded for their intelligence")4 Analysis
4.1 Descriptives
Show the code
datos.pension <- df_study1 %>%
mutate(just_pension = factor(just_pension,
levels = c("Strongly agree",
"Agree",
"Neither agree nor disagree",
"Disagree",
"Strongly disagree"))) %>%
group_by(idencuesta, ola) %>%
count(just_pension) %>%
group_by(ola) %>%
mutate(porcentaje=n/sum(n)) %>%
ungroup() %>%
na.omit() %>%
mutate(wave = case_when(ola == 1 ~ "2016",
ola == 2 ~ "2017",
ola == 3 ~ "2018",
ola == 4 ~ "2019",
ola == 5 ~ "2022",
ola == 6 ~ "2023"),
wave = factor(wave, levels = c("2016",
"2017",
"2018",
"2019",
"2022",
"2023")))
etiquetas.pension <- df_study1 %>%
mutate(just_pension = factor(just_pension,
levels = c("Strongly agree",
"Agree",
"Neither agree nor disagree",
"Disagree",
"Strongly disagree"))) %>%
group_by(ola, just_pension) %>%
summarise(count = n(), .groups = "drop") %>%
group_by(ola) %>%
mutate(porcentaje = count / sum(count)) %>%
na.omit() %>%
mutate(idencuesta = 1,
wave = case_when(ola == 1 ~ "2016",
ola == 2 ~ "2017",
ola == 3 ~ "2018",
ola == 4 ~ "2019",
ola == 5 ~ "2022",
ola == 6 ~ "2023"),
wave = factor(wave, levels = c("2016",
"2017",
"2018",
"2019",
"2022",
"2023")))
datos.pension %>%
ggplot(aes(x = wave, fill = just_pension, stratum = just_pension,
alluvium = idencuesta, y = porcentaje)) +
ggalluvial::geom_flow(alpha = .4) +
ggalluvial::geom_stratum(linetype = 0) +
scale_y_continuous(labels = scales::percent) +
scale_fill_manual(values = c("#0571B0","#92C5DE","#b3b3b3ff","#F4A582","#CA0020")) +
geom_shadowtext(data = etiquetas.pension,
aes(label = ifelse(porcentaje > 0 , scales::percent(porcentaje, accuracy = .1),"")),
position = position_stack(vjust = .5),
show.legend = FALSE,
size = 3,
color = rep('white'),
bg.colour='grey30')+
labs(y = "%",
x = NULL,
fill = NULL,
title = NULL) +
theme_ggdist() +
theme(legend.position = "bottom") 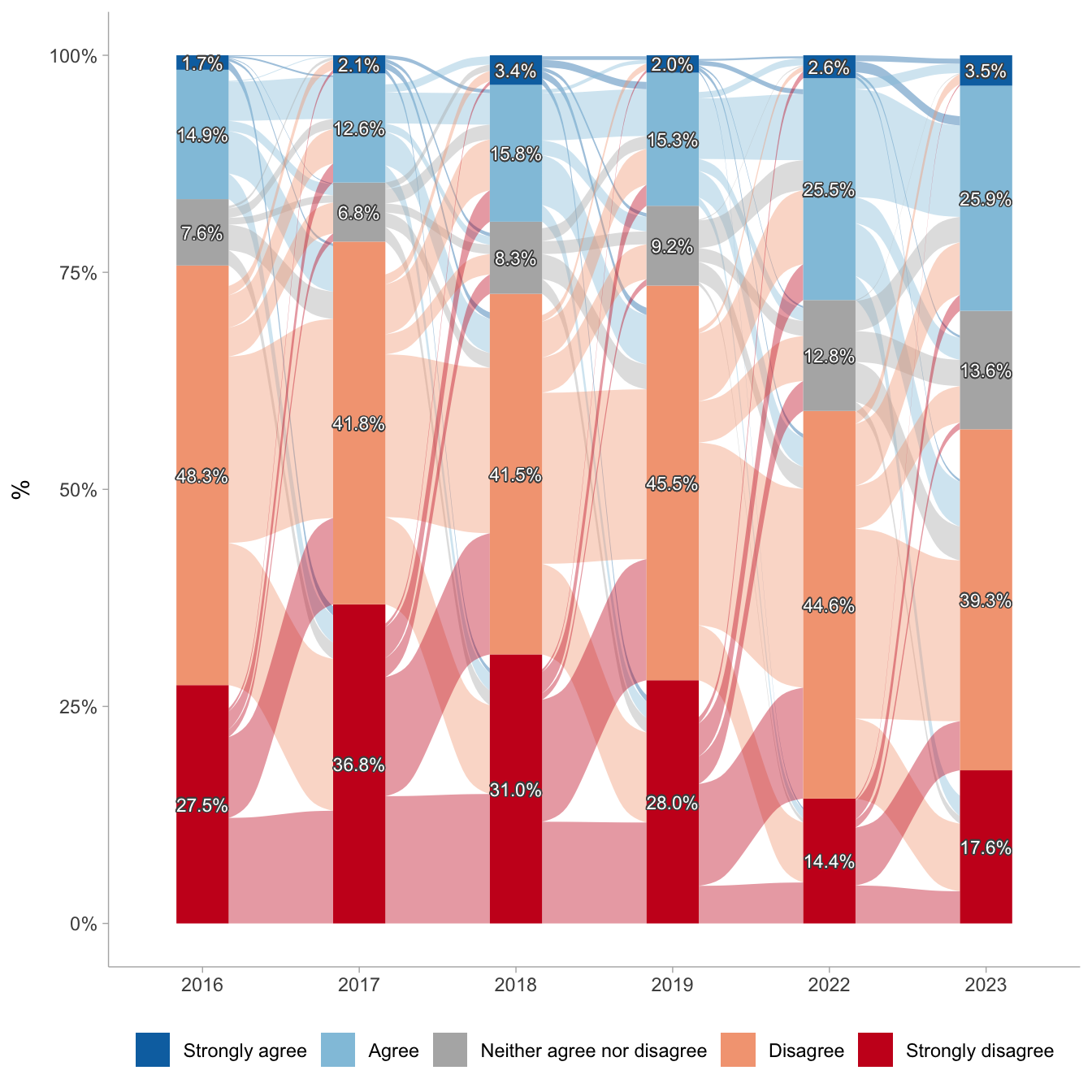
Show the code
Data Frame Summary
t2
Dimensions: 1026 x 4Duplicates: 855
| No | Variable | Label | Stats / Values | Freqs (% of Valid) | Graph | Valid | Missing | |||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | just_pension [factor] | Pension distributive justice |
|
|
 |
1026 (100.0%) | 0 (0.0%) | |||||||||||||||||||||||||
| 2 | egp [factor] | Social class |
|
|
 |
1026 (100.0%) | 0 (0.0%) | |||||||||||||||||||||||||
| 3 | merit_effort [factor] | People are rewarded for their efforts |
|
|
 |
1026 (100.0%) | 0 (0.0%) | |||||||||||||||||||||||||
| 4 | merit_talent [factor] | People are rewarded for their intelligence |
|
|
 |
1026 (100.0%) | 0 (0.0%) |
Generated by summarytools 1.1.4 (R version 4.2.3)
2025-10-16
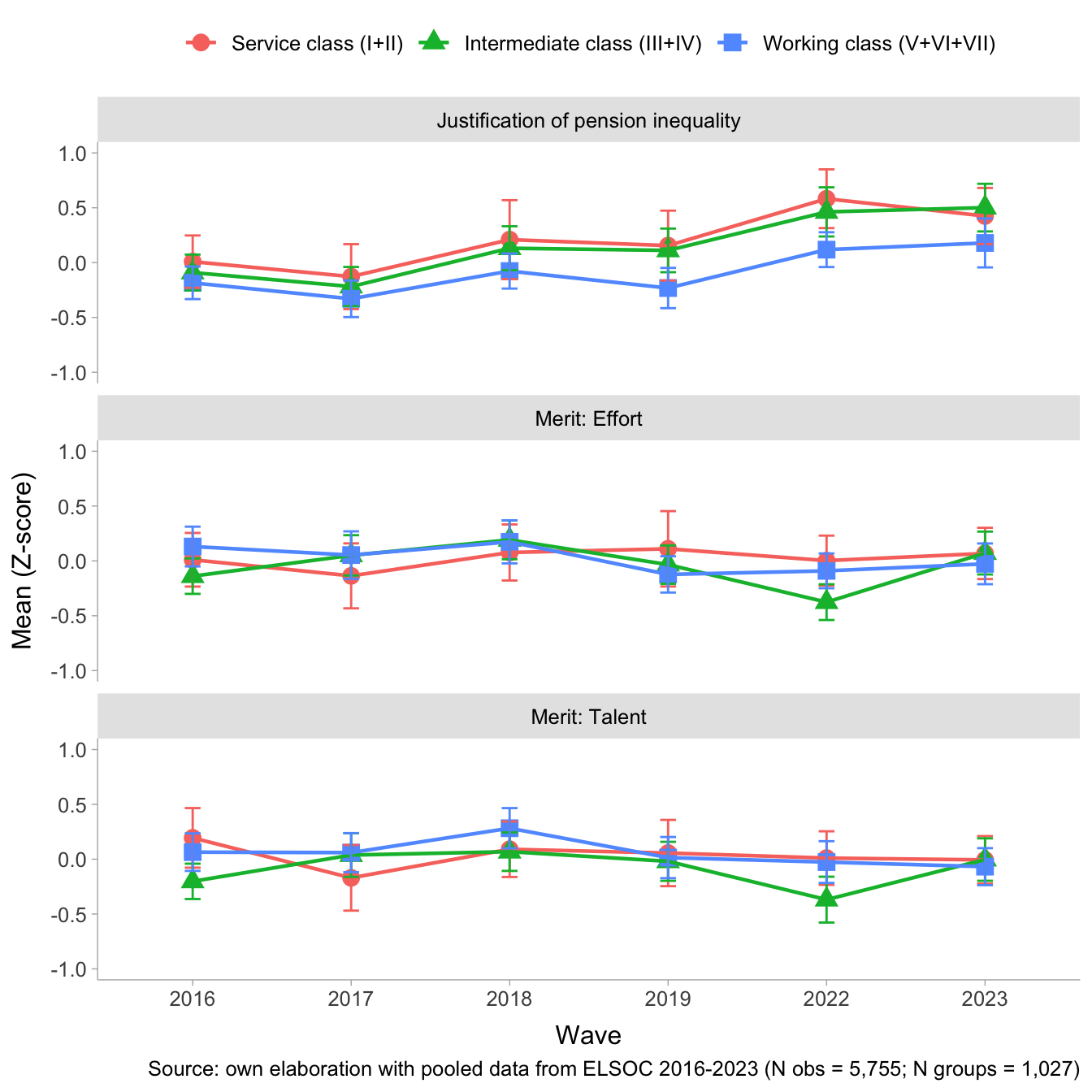
4.2 Longitudinal multilevel models
4.3 ICC
Show the code
m0 <- clmm(just_pension ~ 1 + (1 | idencuesta),
link = "logit",
Hess = TRUE, # calcula explícitamente la matriz varianza-covarianza de estimadores
data = df_study1)
performance::icc(m0, by_group = T) # 0.23 es between, 0.77 within# ICC by Group
Group | ICC
------------------
idencuesta | 0.2304.4 Time effects
Show the code
#m1.1 <- clmm(just_pension ~ 1 + ola + (1 | idencuesta),
# link = "logit",
# Hess = TRUE,
# data = df_study1)
#
#m1.2 <- clmm(just_pension ~ 1 + ola_num + (1 | idencuesta),
# link = "logit",
# Hess = TRUE, data = df_study1)
#
#m1.3 <- clmm(just_pension ~ 1 + ola_num + ola_2 + (1| idencuesta),
# link = "logit",
# Hess = TRUE, data = df_study1)
#
#m1.4 <- clmm(just_pension ~ 1 + ola_num + (1 + ola_num | idencuesta),
# link = "logit",
# Hess = TRUE, data = df_study1)
#
#save(m1.1,m1.2,m1.3,m1.4, file = here("output/time_effects.RData"))
load(file = here("output/time_effects.RData"))
ccoef <- list(
"Strongly disagree|Disagree" = "Strongly disagree|Disagree",
"Disagree|Neither agree nor disagree" = "Disagree|Neither agree nor disagree",
"Neither agree nor disagree|Agree" = "Neither agree nor disagree|Agree",
"Agree|Strongly agree" = "Agree|Strongly agree",
"ola2017" = "Wave 2017",
"ola2018" = "Wave 2018",
"ola2019" = "Wave 2019",
"ola2022" = "Wave 2022",
"ola2023" = "Wave 2023",
ola_num = "Wave",
ola_2 = "Wave^2")
texreg::htmlreg(list(m1.1,m1.2,m1.3,m1.4),
caption.above = T,
caption = NULL,
stars = c(0.05, 0.01, 0.001),
custom.coef.map = ccoef,
digits = 3,
groups = list("Wave (Ref.= 2016)" = 5:9),
custom.note = "Note: Cells contain regression coefficients with standard errors in parentheses. %stars.",
leading.zero = T,
use.packages = F,
booktabs = F,
scalebox = 0.80,
include.loglik = FALSE,
include.aic = FALSE,
center = T)| Model 1 | Model 2 | Model 3 | Model 4 | |
|---|---|---|---|---|
| Strongly disagree|Disagree | -1.104*** | -0.560*** | -1.115*** | -0.575*** |
| (0.072) | (0.067) | (0.115) | (0.069) | |
| Disagree|Neither agree nor disagree | 1.254*** | 1.764*** | 1.221*** | 1.791*** |
| (0.072) | (0.072) | (0.115) | (0.075) | |
| Neither agree nor disagree|Agree | 1.904*** | 2.406*** | 1.867*** | 2.447*** |
| (0.076) | (0.076) | (0.117) | (0.080) | |
| Agree|Strongly agree | 4.521*** | 5.003*** | 4.473*** | 5.088*** |
| (0.114) | (0.115) | (0.145) | (0.122) | |
| Wave (Ref.= 2016) | ||||
| Wave 2017 | -0.370*** | |||
| (0.087) | ||||
| Wave 2018 | 0.028 | |||
| (0.087) | ||||
| Wave 2019 | 0.051 | |||
| (0.086) | ||||
| Wave 2022 | 0.850*** | |||
| (0.088) | ||||
| Wave 2023 | 0.830*** | |||
| (0.085) | ||||
| Wave | 0.217*** | -0.198** | 0.220*** | |
| (0.015) | (0.071) | (0.016) | ||
| Wave^2 | 0.059*** | |||
| (0.010) | ||||
| BIC | 14781.285 | 14838.135 | 14811.280 | 14848.231 |
| Num. obs. | 5755 | 5755 | 5755 | 5755 |
| Groups (idencuesta) | 1027 | 1027 | 1027 | 1027 |
| Variance: idencuesta: (Intercept) | 1.109 | 1.071 | 1.081 | 1.238 |
| Variance: idencuesta: ola_num | 0.025 | |||
| Note: Cells contain regression coefficients with standard errors in parentheses. ***p < 0.001; **p < 0.01; *p < 0.05. | ||||
4.4.1 Anova
Show the code
anova(m1.2, m1.4) # quedarse con tiempo continua y con pendiente aleatoriaLikelihood ratio tests of cumulative link models:
formula: link: threshold:
m1.2 just_pension ~ 1 + ola_num + (1 | idencuesta) logit flexible
m1.4 just_pension ~ 1 + ola_num + (1 + ola_num | idencuesta) logit flexible
no.par AIC logLik LR.stat df Pr(>Chisq)
m1.2 6 14798 -7393.1
m1.4 8 14795 -7389.5 7.2199 2 0.02705 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 14.5 WE and BE main effects
Show the code
## WE and BE main effects
#m3 <- clmm(just_pension ~ 1 + ola_num + egp + (1 + ola_num | idencuesta),
# link = "logit",
# Hess = TRUE,
# data = df_study1)
#
#m4 <- clmm(just_pension ~ 1 + ola_num + egp + merit_effort_cwc + #merit_talent_cwc + (1 + ola_num | idencuesta),
# link = "logit",
# Hess = TRUE,
# data = df_study1)
#
#m5 <- clmm(just_pension ~ 1 + ola_num + egp + merit_effort_cwc + #merit_talent_cwc + merit_effort_mean + merit_talent_mean + (1 + ola_num| #idencuesta),
# link = "logit",
# Hess = TRUE,
# data = df_study1)
#
#m6 <- clmm(just_pension ~ 1 + ola_num + egp + merit_effort_cwc + merit_talent_cwc #+ merit_effort_mean + merit_talent_mean + educ + ideo + sex + age + (1 + ola_num| #idencuesta),
# link = "logit",
# Hess = TRUE,
# data = df_study1)
#
#save(m3,m4,m5,m6, file = here("output/main_effects.RData"))
load(file = here("output/main_effects.RData"))
ccoef <- list(
"Strongly disagree|Disagree" = "Strongly disagree|Disagree",
"Disagree|Neither agree nor disagree" = "Disagree|Neither agree nor disagree",
"Neither agree nor disagree|Agree" = "Neither agree nor disagree|Agree",
"Agree|Strongly agree" = "Agree|Strongly agree",
ola_num = "Wave",
"egpIntermediate class (III+IV)" = "Intermediate class (III+IV)",
"egpService class (I+II)" = "Service class (I+II)",
merit_effort_cwc = "Merit: Effort (WE)",
merit_talent_cwc = "Merit: Talent (WE)",
merit_effort_mean = "Merit: Effort (BE)",
merit_talent_mean = "Merit: Talent (BE)",
"educUniversitary" = "Universitary education (Ref.= Less than Universitary)",
ideoCenter = "Center",
ideoRight = "Right",
"ideoDoes not identify" = "Does not identify",
sexFemale = "Female (Ref.= Male)",
age = "Age"
)
texreg::htmlreg(list(m3,m4,m5,m6),
caption.above = T,
caption = NULL,
stars = c(0.05, 0.01, 0.001),
custom.coef.map = ccoef,
digits = 3,
groups = list("Social Class (Ref.= Working class (V+VI+VII))" = 6:7,
"Political identification (Ref.= Left)" = 13:15),
custom.note = "Note: Cells contain regression coefficients with standard errors in parentheses. %stars.",
leading.zero = T,
use.packages = F,
booktabs = F,
scalebox = 0.80,
include.loglik = FALSE,
include.aic = FALSE,
center = T)| Model 1 | Model 2 | Model 3 | Model 4 | |
|---|---|---|---|---|
| Strongly disagree|Disagree | -0.482*** | -0.469*** | 0.976*** | 0.779** |
| (0.085) | (0.085) | (0.212) | (0.259) | |
| Disagree|Neither agree nor disagree | 1.884*** | 1.902*** | 3.347*** | 3.150*** |
| (0.090) | (0.090) | (0.218) | (0.264) | |
| Neither agree nor disagree|Agree | 2.540*** | 2.558*** | 4.003*** | 3.808*** |
| (0.095) | (0.095) | (0.221) | (0.266) | |
| Agree|Strongly agree | 5.181*** | 5.199*** | 6.645*** | 6.455*** |
| (0.133) | (0.133) | (0.243) | (0.285) | |
| Wave | 0.220*** | 0.224*** | 0.223*** | 0.224*** |
| (0.016) | (0.016) | (0.016) | (0.016) | |
| Social Class (Ref.= Working class (V+VI+VII)) | ||||
| Intermediate class (III+IV) | 0.123 | 0.123 | 0.153 | 0.196* |
| (0.090) | (0.090) | (0.088) | (0.088) | |
| Service class (I+II) | 0.267* | 0.268* | 0.260* | 0.085 |
| (0.128) | (0.128) | (0.125) | (0.144) | |
| Merit: Effort (WE) | 0.170*** | 0.172*** | 0.172*** | |
| (0.041) | (0.041) | (0.041) | ||
| Merit: Talent (WE) | 0.037 | 0.037 | 0.038 | |
| (0.040) | (0.040) | (0.040) | ||
| Merit: Effort (BE) | 0.449*** | 0.425*** | ||
| (0.113) | (0.110) | |||
| Merit: Talent (BE) | 0.102 | 0.062 | ||
| (0.111) | (0.108) | |||
| Universitary education (Ref.= Less than Universitary) | 0.343** | |||
| (0.122) | ||||
| Political identification (Ref.= Left) | ||||
| Center | 0.251* | |||
| (0.122) | ||||
| Right | 0.669*** | |||
| (0.141) | ||||
| Does not identify | 0.167 | |||
| (0.105) | ||||
| Female (Ref.= Male) | -0.421*** | |||
| (0.082) | ||||
| Age | -0.001 | |||
| (0.003) | ||||
| BIC | 14860.778 | 14839.799 | 14799.102 | 14790.003 |
| Num. obs. | 5755 | 5755 | 5755 | 5755 |
| Groups (idencuesta) | 1027 | 1027 | 1027 | 1027 |
| Variance: idencuesta: (Intercept) | 1.222 | 1.179 | 0.987 | 0.902 |
| Variance: idencuesta: ola_num | 0.025 | 0.020 | 0.019 | 0.020 |
| Note: Cells contain regression coefficients with standard errors in parentheses. ***p < 0.001; **p < 0.01; *p < 0.05. | ||||
4.6 Interactions without controls (total effect)
Show the code
# ## WE and BE Interactions without controls
#m7 <- clmm(just_pension ~ 1 + ola_num + egp + merit_effort_cwc + merit_talent_cwc #+ merit_effort_mean + merit_talent_mean + egp*merit_effort_cwc + (1 + ola_num + #merit_effort_cwc| idencuesta),
# link = "logit",
# Hess = TRUE,
# data = df_study1)
#
#m8 <- clmm(just_pension ~ 1 + ola_num + egp + merit_effort_cwc + merit_talent_cwc #+ merit_effort_mean + merit_talent_mean + egp*merit_talent_cwc + (1 + ola_num + #merit_talent_cwc| idencuesta),
# link = "logit",
# Hess = TRUE,
# data = df_study1)
#
#
#m9 <- clmm(just_pension ~ 1 + ola_num + egp + merit_effort_cwc + merit_talent_cwc #+ merit_effort_mean + merit_talent_mean + egp*merit_effort_mean + (1 + ola_num + #merit_effort_mean| idencuesta),
# link = "logit",
# Hess = TRUE,
# data = df_study1)
#
#m10 <- clmm(just_pension ~ 1 + ola_num + egp + merit_effort_cwc + #merit_talent_cwc + merit_effort_mean + merit_talent_mean + egp*merit_talent_mean #+ (1 + ola_num + merit_talent_mean| idencuesta),
# link = "logit",
# Hess = TRUE,
# data = df_study1)
#
#save(m7,m8,m9,m10, file = here("output/interactions_total.RData"))
load(file = here("output/interactions_total.RData"))
ccoef <- list(
"Strongly disagree|Disagree" = "Strongly disagree|Disagree",
"Disagree|Neither agree nor disagree" = "Disagree|Neither agree nor disagree",
"Neither agree nor disagree|Agree" = "Neither agree nor disagree|Agree",
"Agree|Strongly agree" = "Agree|Strongly agree",
"egpIntermediate class (III+IV)" = "Intermediate class (III+IV)",
"egpService class (I+II)" = "Service class (I+II)",
merit_effort_cwc = "Merit: Effort (WE)",
merit_talent_cwc = "Merit: Talent (WE)",
merit_effort_mean = "Merit: Effort (BE)",
merit_talent_mean = "Merit: Talent (BE)",
"egpIntermediate class (III+IV):merit_effort_cwc" = "Intermediate class (III+IV) x Merit: Effort (WE)",
"egpService class (I+II):merit_effort_cwc" = "Service class (I+II) x Merit: Effort (WE)",
"egpIntermediate class (III+IV):merit_talent_cwc" = "Intermediate class (III+IV) x Merit: Talent (WE)",
"egpService class (I+II):merit_talent_cwc" = "Service class (I+II) x Merit: Talent (WE)",
"egpIntermediate class (III+IV):merit_effort_mean" = "Intermediate class (III+IV) x Merit: Effort (BE)",
"egpService class (I+II):merit_effort_mean" = "Service class (I+II) x Merit: Effort (BE)",
"egpIntermediate class (III+IV):merit_talent_mean" = "Intermediate class (III+IV) x Merit: Talent (BE)",
"egpService class (I+II):merit_talent_mean" = "Service class (I+II) x Merit: Talent (BE)")
texreg::htmlreg(list(m7,m8,m9,m10),
caption.above = T,
caption = NULL,
stars = c(0.05, 0.01, 0.001),
custom.coef.map = ccoef,
digits = 3,
groups = list("Social Class (Ref.= Working class (V+VI+VII))" = 5:6,
"Social Class (Ref.= Working class (V+VI+VII)) x Meritocracy (WE)" = 11:14,
"Social Class (Ref.= Working class (V+VI+VII)) x Meritocracy (BE)" = 15:18),
custom.note = "Note: Cells contain regression coefficients with standard errors in parentheses. %stars.",
leading.zero = T,
use.packages = F,
booktabs = F,
scalebox = 0.80,
include.loglik = FALSE,
include.aic = FALSE,
center = T,
custom.gof.rows = list("Controls"=c(rep("No",4))))| Model 1 | Model 2 | Model 3 | Model 4 | |
|---|---|---|---|---|
| Strongly disagree|Disagree | 0.952*** | 0.974*** | 0.735* | 0.750* |
| (0.214) | (0.214) | (0.314) | (0.320) | |
| Disagree|Neither agree nor disagree | 3.350*** | 3.380*** | 3.104*** | 3.120*** |
| (0.222) | (0.222) | (0.318) | (0.324) | |
| Neither agree nor disagree|Agree | 4.012*** | 4.043*** | 3.759*** | 3.775*** |
| (0.225) | (0.225) | (0.320) | (0.326) | |
| Agree|Strongly agree | 6.666*** | 6.703*** | 6.403*** | 6.417*** |
| (0.248) | (0.248) | (0.335) | (0.341) | |
| Social Class (Ref.= Working class (V+VI+VII)) | ||||
| Intermediate class (III+IV) | 0.154 | 0.155 | -0.437 | -0.263 |
| (0.089) | (0.089) | (0.420) | (0.432) | |
| Service class (I+II) | 0.265* | 0.266* | 0.481 | 0.251 |
| (0.126) | (0.126) | (0.589) | (0.600) | |
| Merit: Effort (WE) | 0.134* | 0.174*** | 0.172*** | 0.172*** |
| (0.058) | (0.042) | (0.041) | (0.041) | |
| Merit: Talent (WE) | 0.038 | -0.006 | 0.037 | 0.038 |
| (0.041) | (0.057) | (0.040) | (0.040) | |
| Merit: Effort (BE) | 0.444*** | 0.462*** | 0.372** | 0.443*** |
| (0.114) | (0.114) | (0.142) | (0.112) | |
| Merit: Talent (BE) | 0.097 | 0.090 | 0.088 | 0.026 |
| (0.112) | (0.113) | (0.110) | (0.141) | |
| Social Class (Ref.= Working class (V+VI+VII)) x Meritocracy (WE) | ||||
| Intermediate class (III+IV) x Merit: Effort (WE) | 0.074 | |||
| (0.071) | ||||
| Service class (I+II) x Merit: Effort (WE) | 0.018 | |||
| (0.107) | ||||
| Intermediate class (III+IV) x Merit: Talent (WE) | 0.080 | |||
| (0.071) | ||||
| Service class (I+II) x Merit: Talent (WE) | 0.071 | |||
| (0.107) | ||||
| Social Class (Ref.= Working class (V+VI+VII)) x Meritocracy (BE) | ||||
| Intermediate class (III+IV) x Merit: Effort (BE) | 0.229 | |||
| (0.159) | ||||
| Service class (I+II) x Merit: Effort (BE) | -0.091 | |||
| (0.220) | ||||
| Intermediate class (III+IV) x Merit: Talent (BE) | 0.151 | |||
| (0.155) | ||||
| Service class (I+II) x Merit: Talent (BE) | -0.002 | |||
| (0.211) | ||||
| Controls | No | No | No | No |
| BIC | 14832.108 | 14830.095 | 14831.984 | 14836.288 |
| Num. obs. | 5755 | 5755 | 5755 | 5755 |
| Groups (idencuesta) | 1027 | 1027 | 1027 | 1027 |
| Variance: idencuesta: (Intercept) | 1.003 | 1.003 | 3.889 | 3.287 |
| Variance: idencuesta: ola_num | 0.017 | 0.017 | 0.019 | 0.019 |
| Variance: idencuesta: merit_effort_cwc | 0.079 | |||
| Variance: idencuesta: merit_talent_cwc | 0.092 | |||
| Variance: idencuesta: merit_effort_mean | 0.407 | |||
| Variance: idencuesta: merit_talent_mean | 0.330 | |||
| Note: Cells contain regression coefficients with standard errors in parentheses. ***p < 0.001; **p < 0.01; *p < 0.05. | ||||
4.7 Interactions with controls (direct effect)
Show the code
# ## WE and BE Interactions with controls
#m11 <- clmm(just_pension ~ 1 + ola_num + egp + merit_effort_cwc + #merit_talent_cwc + merit_effort_mean + merit_talent_mean + ideo + sex + age + #egp*merit_effort_cwc + (1 + ola_num + merit_effort_cwc| idencuesta),
# link = "logit",
# Hess = TRUE,
# data = df_study1)
#
#m12 <- clmm(just_pension ~ 1 + ola_num + egp + merit_effort_cwc + #merit_talent_cwc + merit_effort_mean + merit_talent_mean + ideo + sex + age + #egp*merit_talent_cwc + (1 + ola_num + merit_talent_cwc| idencuesta),
# link = "logit",
# Hess = TRUE,
# data = df_study1)
#
#
#m13 <- clmm(just_pension ~ 1 + ola_num + egp + merit_effort_cwc + #merit_talent_cwc + merit_effort_mean + merit_talent_mean + ideo + sex + age + #egp*merit_effort_mean + (1 + ola_num + merit_effort_mean| idencuesta),
# link = "logit",
# Hess = TRUE,
# data = df_study1)
#
#m14 <- clmm(just_pension ~ 1 + ola_num + egp + merit_effort_cwc + #merit_talent_cwc + merit_effort_mean + merit_talent_mean + ideo + sex + age + #egp*merit_talent_mean + (1 + ola_num + merit_talent_mean| idencuesta),
# link = "logit",
# Hess = TRUE,
# data = df_study1)
#
#save(m11,m12,m13,m14, file = here("output/interactions_direct.RData"))
load(file = here("output/interactions_direct.RData"))
ccoef <- list(
"Strongly disagree|Disagree" = "Strongly disagree|Disagree",
"Disagree|Neither agree nor disagree" = "Disagree|Neither agree nor disagree",
"Neither agree nor disagree|Agree" = "Neither agree nor disagree|Agree",
"Agree|Strongly agree" = "Agree|Strongly agree",
"egpIntermediate class (III+IV)" = "Intermediate class (III+IV)",
"egpService class (I+II)" = "Service class (I+II)",
merit_effort_cwc = "Merit: Effort (WE)",
merit_talent_cwc = "Merit: Talent (WE)",
merit_effort_mean = "Merit: Effort (BE)",
merit_talent_mean = "Merit: Talent (BE)",
"egpIntermediate class (III+IV):merit_effort_cwc" = "Intermediate class (III+IV) x Merit: Effort (WE)",
"egpService class (I+II):merit_effort_cwc" = "Service class (I+II) x Merit: Effort (WE)",
"egpIntermediate class (III+IV):merit_talent_cwc" = "Intermediate class (III+IV) x Merit: Talent (WE)",
"egpService class (I+II):merit_talent_cwc" = "Service class (I+II) x Merit: Talent (WE)",
"egpIntermediate class (III+IV):merit_effort_mean" = "Intermediate class (III+IV) x Merit: Effort (BE)",
"egpService class (I+II):merit_effort_mean" = "Service class (I+II) x Merit: Effort (BE)",
"egpIntermediate class (III+IV):merit_talent_mean" = "Intermediate class (III+IV) x Merit: Talent (BE)",
"egpService class (I+II):merit_talent_mean" = "Service class (I+II) x Merit: Talent (BE)")
texreg::htmlreg(list(m11,m12,m13,m14),
caption.above = T,
caption = NULL,
stars = c(0.05, 0.01, 0.001),
custom.coef.map = ccoef,
digits = 3,
groups = list("Social Class (Ref.= Working class (V+VI+VII))" = 5:6,
"Social Class (Ref.= Working class (V+VI+VII)) x Meritocracy (WE)" = 11:14,
"Social Class (Ref.= Working class (V+VI+VII)) x Meritocracy (BE)" = 15:18),
custom.note = "Note: Cells contain regression coefficients with standard errors in parentheses. %stars.",
leading.zero = T,
use.packages = F,
booktabs = F,
scalebox = 0.80,
include.loglik = FALSE,
include.aic = FALSE,
center = T,
custom.gof.rows = list("Controls"=c(rep("Yes",4))))| Model 1 | Model 2 | Model 3 | Model 4 | |
|---|---|---|---|---|
| Strongly disagree|Disagree | 0.631* | 0.650* | 0.299 | 0.502 |
| (0.259) | (0.259) | (0.348) | (0.334) | |
| Disagree|Neither agree nor disagree | 3.030*** | 3.056*** | 2.669*** | 2.854*** |
| (0.264) | (0.264) | (0.350) | (0.337) | |
| Neither agree nor disagree|Agree | 3.693*** | 3.722*** | 3.326*** | 3.512*** |
| (0.266) | (0.267) | (0.352) | (0.339) | |
| Agree|Strongly agree | 6.352*** | 6.386*** | 5.971*** | 6.173*** |
| (0.286) | (0.286) | (0.365) | (0.353) | |
| Social Class (Ref.= Working class (V+VI+VII)) | ||||
| Intermediate class (III+IV) | 0.233** | 0.234** | -0.436 | -0.270 |
| (0.088) | (0.088) | (0.412) | (0.391) | |
| Service class (I+II) | 0.300* | 0.302* | 0.323 | 0.264 |
| (0.125) | (0.125) | (0.577) | (0.543) | |
| Merit: Effort (WE) | 0.136* | 0.174*** | 0.172*** | 0.171*** |
| (0.058) | (0.042) | (0.041) | (0.041) | |
| Merit: Talent (WE) | 0.039 | -0.004 | 0.038 | 0.038 |
| (0.041) | (0.057) | (0.040) | (0.040) | |
| Merit: Effort (BE) | 0.423*** | 0.439*** | 0.328* | 0.442*** |
| (0.111) | (0.112) | (0.138) | (0.111) | |
| Merit: Talent (BE) | 0.045 | 0.038 | 0.032 | -0.025 |
| (0.109) | (0.110) | (0.108) | (0.135) | |
| Social Class (Ref.= Working class (V+VI+VII)) x Meritocracy (WE) | ||||
| Intermediate class (III+IV) x Merit: Effort (WE) | 0.072 | |||
| (0.071) | ||||
| Service class (I+II) x Merit: Effort (WE) | 0.016 | |||
| (0.107) | ||||
| Intermediate class (III+IV) x Merit: Talent (WE) | 0.078 | |||
| (0.071) | ||||
| Service class (I+II) x Merit: Talent (WE) | 0.071 | |||
| (0.107) | ||||
| Social Class (Ref.= Working class (V+VI+VII)) x Meritocracy (BE) | ||||
| Intermediate class (III+IV) x Merit: Effort (BE) | 0.259 | |||
| (0.155) | ||||
| Service class (I+II) x Merit: Effort (BE) | -0.018 | |||
| (0.215) | ||||
| Intermediate class (III+IV) x Merit: Talent (BE) | 0.184 | |||
| (0.145) | ||||
| Service class (I+II) x Merit: Talent (BE) | 0.010 | |||
| (0.199) | ||||
| Controls | Yes | Yes | Yes | Yes |
| BIC | 14823.107 | 14820.462 | 14820.991 | 14853.242 |
| Num. obs. | 5755 | 5755 | 5755 | 5755 |
| Groups (idencuesta) | 1027 | 1027 | 1027 | 1027 |
| Variance: idencuesta: (Intercept) | 0.937 | 0.938 | 3.839 | 0.000 |
| Variance: idencuesta: ola_num | 0.018 | 0.018 | 0.020 | 0.023 |
| Variance: idencuesta: merit_effort_cwc | 0.079 | |||
| Variance: idencuesta: merit_talent_cwc | 0.094 | |||
| Variance: idencuesta: merit_effort_mean | 0.414 | |||
| Variance: idencuesta: merit_talent_mean | 0.089 | |||
| Note: Cells contain regression coefficients with standard errors in parentheses. ***p < 0.001; **p < 0.01; *p < 0.05. | ||||
4.8 Interactions with meritocratic variables as dichotomized variables without controls
Show the code
## WE and BE Interactions merit dummy
#m15 <- clmm(just_pension ~ 1 + ola_num + egp + merit_effort_dic_cwc + #merit_talent_dic_cwc + merit_effort_dic_mean + merit_talent_dic_mean + #egp*merit_effort_dic_cwc + (1 + ola_num + merit_effort_dic_cwc| idencuesta),
# link = "logit",
# Hess = TRUE,
# data = df_study1)
#
#m16 <- clmm(just_pension ~ 1 + ola_num + egp + merit_effort_dic_cwc + #merit_talent_dic_cwc + merit_effort_dic_mean + merit_talent_dic_mean + #egp*merit_talent_dic_cwc + (1 + ola_num + merit_talent_dic_cwc| idencuesta),
# link = "logit",
# Hess = TRUE,
# data = df_study1)
#
#
#m17 <- clmm(just_pension ~ 1 + ola_num + egp + merit_effort_dic_cwc + #merit_talent_dic_cwc + merit_effort_dic_mean + merit_talent_dic_mean + #egp*merit_effort_dic_mean + (1 + ola_num + merit_effort_dic_mean| idencuesta),
# link = "logit",
# Hess = TRUE,
# data = df_study1)
#
#m18 <- clmm(just_pension ~ 1 + ola_num + egp + merit_effort_dic_cwc + #merit_talent_dic_cwc + merit_effort_dic_mean + merit_talent_dic_mean + #egp*merit_talent_dic_mean + (1 + ola_num + merit_talent_dic_mean| idencuesta),
# link = "logit",
# Hess = TRUE,
# data = df_study1)
#
#save(m15,m16,m17,m18, file = here("output/interactions_total_dico.RData"))
load(file = here("output/interactions_total_dico.RData"))
ccoef <- list(
"Strongly disagree|Disagree" = "Strongly disagree|Disagree",
"Disagree|Neither agree nor disagree" = "Disagree|Neither agree nor disagree",
"Neither agree nor disagree|Agree" = "Neither agree nor disagree|Agree",
"Agree|Strongly agree" = "Agree|Strongly agree",
"egpIntermediate class (III+IV)" = "Intermediate class (III+IV)",
"egpService class (I+II)" = "Service class (I+II)",
merit_effort_dic_cwc = "Merit: Effort (WE)",
merit_talent_dic_cwc = "Merit: Talent (WE)",
merit_effort_dic_mean = "Merit: Effort (BE)",
merit_talent_dic_mean = "Merit: Talent (BE)",
"egpIntermediate class (III+IV):merit_effort_dic_cwc" = "Intermediate class (III+IV) x Merit: Effort (WE)",
"egpService class (I+II):merit_effort_dic_cwc" = "Service class (I+II) x Merit: Effort (WE)",
"egpIntermediate class (III+IV):merit_talent_dic_cwc" = "Intermediate class (III+IV) x Merit: Talent (WE)",
"egpService class (I+II):merit_talent_dic_cwc" = "Service class (I+II) x Merit: Talent (WE)",
"egpIntermediate class (III+IV):merit_effort_dic_mean" = "Intermediate class (III+IV) x Merit: Effort (BE)",
"egpService class (I+II):merit_effort_dic_mean" = "Service class (I+II) x Merit: Effort (BE)",
"egpIntermediate class (III+IV):merit_talent_dic_mean" = "Intermediate class (III+IV) x Merit: Talent (BE)",
"egpService class (I+II):merit_talent_dic_mean" = "Service class (I+II) x Merit: Talent (BE)")
texreg::htmlreg(list(m15,m16,m17,m18),
caption.above = T,
caption = NULL,
stars = c(0.05, 0.01, 0.001),
custom.coef.map = ccoef,
digits = 3,
groups = list("Social Class (Ref.= Working class (V+VI+VII))" = 5:6,
"Social Class (Ref.= Working class (V+VI+VII)) x Meritocracy (WE)" = 11:14,
"Social Class (Ref.= Working class (V+VI+VII)) x Meritocracy (BE)" = 15:18),
custom.note = "Note: Cells contain regression coefficients with standard errors in parentheses. %stars.",
leading.zero = T,
use.packages = F,
booktabs = F,
scalebox = 0.80,
include.loglik = FALSE,
include.aic = FALSE,
center = T,
custom.gof.rows = list("Controls"=c(rep("No",4))))| Model 1 | Model 2 | Model 3 | Model 4 | |
|---|---|---|---|---|
| Strongly disagree|Disagree | -0.257** | -0.260** | -0.315** | -0.305** |
| (0.098) | (0.098) | (0.109) | (0.116) | |
| Disagree|Neither agree nor disagree | 2.114*** | 2.111*** | 2.048*** | 2.058*** |
| (0.104) | (0.104) | (0.115) | (0.121) | |
| Neither agree nor disagree|Agree | 2.772*** | 2.769*** | 2.705*** | 2.714*** |
| (0.108) | (0.108) | (0.119) | (0.125) | |
| Agree|Strongly agree | 5.420*** | 5.418*** | 5.351*** | 5.358*** |
| (0.144) | (0.144) | (0.151) | (0.157) | |
| Social Class (Ref.= Working class (V+VI+VII)) | ||||
| Intermediate class (III+IV) | 0.147 | 0.146 | 0.028 | 0.086 |
| (0.089) | (0.089) | (0.127) | (0.140) | |
| Service class (I+II) | 0.289* | 0.288* | 0.239 | 0.197 |
| (0.127) | (0.127) | (0.177) | (0.194) | |
| Merit: Effort (WE) | 0.086 | 0.227* | 0.222* | 0.223* |
| (0.128) | (0.091) | (0.091) | (0.091) | |
| Merit: Talent (WE) | -0.035 | -0.157 | -0.037 | -0.038 |
| (0.084) | (0.116) | (0.084) | (0.084) | |
| Merit: Effort (BE) | 0.627* | 0.624* | 0.401 | 0.620* |
| (0.260) | (0.260) | (0.331) | (0.256) | |
| Merit: Talent (BE) | 0.215 | 0.219 | 0.191 | 0.055 |
| (0.243) | (0.243) | (0.241) | (0.318) | |
| Social Class (Ref.= Working class (V+VI+VII)) x Meritocracy (WE) | ||||
| Intermediate class (III+IV) x Merit: Effort (WE) | 0.303 | |||
| (0.160) | ||||
| Service class (I+II) x Merit: Effort (WE) | -0.042 | |||
| (0.234) | ||||
| Intermediate class (III+IV) x Merit: Talent (WE) | 0.250 | |||
| (0.147) | ||||
| Service class (I+II) x Merit: Talent (WE) | -0.005 | |||
| (0.221) | ||||
| Social Class (Ref.= Working class (V+VI+VII)) x Meritocracy (BE) | ||||
| Intermediate class (III+IV) x Merit: Effort (BE) | 0.525 | |||
| (0.389) | ||||
| Service class (I+II) x Merit: Effort (BE) | 0.179 | |||
| (0.554) | ||||
| Intermediate class (III+IV) x Merit: Talent (BE) | 0.194 | |||
| (0.368) | ||||
| Service class (I+II) x Merit: Talent (BE) | 0.293 | |||
| (0.502) | ||||
| Controls | No | No | No | No |
| BIC | 14904.006 | 14904.716 | 14904.839 | 14903.542 |
| Num. obs. | 5755 | 5755 | 5755 | 5755 |
| Groups (idencuesta) | 1027 | 1027 | 1027 | 1027 |
| Variance: idencuesta: (Intercept) | 1.128 | 1.128 | 1.158 | 1.296 |
| Variance: idencuesta: ola_num | 0.024 | 0.024 | 0.023 | 0.023 |
| Variance: idencuesta: merit_effort_dic_cwc | 0.041 | |||
| Variance: idencuesta: merit_talent_dic_cwc | 0.038 | |||
| Variance: idencuesta: merit_effort_dic_mean | 1.791 | |||
| Variance: idencuesta: merit_talent_dic_mean | 2.522 | |||
| Note: Cells contain regression coefficients with standard errors in parentheses. ***p < 0.001; **p < 0.01; *p < 0.05. | ||||
4.9 Interactions with meritocratic variables as dichotomized variables with controls
Show the code
## WE and BE Interactions merit dummy
#m19 <- clmm(just_pension ~ 1 + ola_num + egp + merit_effort_dic_cwc + #merit_talent_dic_cwc + merit_effort_dic_mean + merit_talent_dic_mean + ideo + sex #+ age + egp*merit_effort_dic_cwc + (1 + ola_num + merit_effort_dic_cwc| #idencuesta),
# link = "logit",
# Hess = TRUE,
# data = df_study1)
#
#m20 <- clmm(just_pension ~ 1 + ola_num + egp + merit_effort_dic_cwc + #merit_talent_dic_cwc + merit_effort_dic_mean + merit_talent_dic_mean + ideo + sex #+ age + egp*merit_talent_dic_cwc + (1 + ola_num + merit_talent_dic_cwc| #idencuesta),
# link = "logit",
# Hess = TRUE,
# data = df_study1)
#
#
#m21 <- clmm(just_pension ~ 1 + ola_num + egp + merit_effort_dic_cwc + #merit_talent_dic_cwc + merit_effort_dic_mean + merit_talent_dic_mean + ideo + sex #+ age + egp*merit_effort_dic_mean + (1 + ola_num + merit_effort_dic_mean| #idencuesta),
# link = "logit",
# Hess = TRUE,
# data = df_study1)
#
#m22 <- clmm(just_pension ~ 1 + ola_num + egp + merit_effort_dic_cwc + #merit_talent_dic_cwc + merit_effort_dic_mean + merit_talent_dic_mean + ideo + sex #+ age + egp*merit_talent_dic_mean + (1 + ola_num + merit_talent_dic_mean| #idencuesta),
# link = "logit",
# Hess = TRUE,
# data = df_study1)
#
#save(m19,m20,m21,m22, file = here("output/interactions_direct_dic.RData"))
load(file = here("output/interactions_direct_dic.RData"))
ccoef <- list(
"Strongly disagree|Disagree" = "Strongly disagree|Disagree",
"Disagree|Neither agree nor disagree" = "Disagree|Neither agree nor disagree",
"Neither agree nor disagree|Agree" = "Neither agree nor disagree|Agree",
"Agree|Strongly agree" = "Agree|Strongly agree",
"egpIntermediate class (III+IV)" = "Intermediate class (III+IV)",
"egpService class (I+II)" = "Service class (I+II)",
merit_effort_dic_cwc = "Merit: Effort (WE)",
merit_talent_dic_cwc = "Merit: Talent (WE)",
merit_effort_dic_mean = "Merit: Effort (BE)",
merit_talent_dic_mean = "Merit: Talent (BE)",
"egpIntermediate class (III+IV):merit_effort_dic_cwc" = "Intermediate class (III+IV) x Merit: Effort (WE)",
"egpService class (I+II):merit_effort_dic_cwc" = "Service class (I+II) x Merit: Effort (WE)",
"egpIntermediate class (III+IV):merit_talent_dic_cwc" = "Intermediate class (III+IV) x Merit: Talent (WE)",
"egpService class (I+II):merit_talent_dic_cwc" = "Service class (I+II) x Merit: Talent (WE)",
"egpIntermediate class (III+IV):merit_effort_dic_mean" = "Intermediate class (III+IV) x Merit: Effort (BE)",
"egpService class (I+II):merit_effort_dic_mean" = "Service class (I+II) x Merit: Effort (BE)",
"egpIntermediate class (III+IV):merit_talent_dic_mean" = "Intermediate class (III+IV) x Merit: Talent (BE)",
"egpService class (I+II):merit_talent_dic_mean" = "Service class (I+II) x Merit: Talent (BE)")
texreg::htmlreg(list(m19,m20,m21,m22),
caption.above = T,
caption = NULL,
stars = c(0.05, 0.01, 0.001),
custom.coef.map = ccoef,
digits = 3,
groups = list("Social Class (Ref.= Working class (V+VI+VII))" = 5:6,
"Social Class (Ref.= Working class (V+VI+VII)) x Meritocracy (WE)" = 11:14,
"Social Class (Ref.= Working class (V+VI+VII)) x Meritocracy (BE)" = 15:18),
custom.note = "Note: Cells contain regression coefficients with standard errors in parentheses. %stars.",
leading.zero = T,
use.packages = F,
booktabs = F,
scalebox = 0.80,
include.loglik = FALSE,
include.aic = FALSE,
center = T,
custom.gof.rows = list("Controls"=c(rep("Yes",4))))| Model 1 | Model 2 | Model 3 | Model 4 | |
|---|---|---|---|---|
| Strongly disagree|Disagree | -0.383* | -0.385* | -0.482* | -0.489* |
| (0.191) | (0.191) | (0.200) | (0.203) | |
| Disagree|Neither agree nor disagree | 1.988*** | 1.986*** | 1.883*** | 1.875*** |
| (0.194) | (0.194) | (0.202) | (0.205) | |
| Neither agree nor disagree|Agree | 2.648*** | 2.646*** | 2.541*** | 2.533*** |
| (0.196) | (0.196) | (0.204) | (0.207) | |
| Agree|Strongly agree | 5.299*** | 5.298*** | 5.189*** | 5.180*** |
| (0.218) | (0.218) | (0.225) | (0.228) | |
| Social Class (Ref.= Working class (V+VI+VII)) | ||||
| Intermediate class (III+IV) | 0.229** | 0.229** | 0.099 | 0.135 |
| (0.089) | (0.089) | (0.124) | (0.137) | |
| Service class (I+II) | 0.326** | 0.325** | 0.245 | 0.188 |
| (0.126) | (0.126) | (0.173) | (0.189) | |
| Merit: Effort (WE) | 0.090 | 0.228* | 0.224* | 0.225* |
| (0.128) | (0.091) | (0.091) | (0.091) | |
| Merit: Talent (WE) | -0.035 | -0.154 | -0.037 | -0.038 |
| (0.084) | (0.117) | (0.084) | (0.084) | |
| Merit: Effort (BE) | 0.589* | 0.587* | 0.323 | 0.587* |
| (0.253) | (0.253) | (0.322) | (0.250) | |
| Merit: Talent (BE) | 0.065 | 0.069 | 0.041 | -0.170 |
| (0.239) | (0.239) | (0.237) | (0.310) | |
| Social Class (Ref.= Working class (V+VI+VII)) x Meritocracy (WE) | ||||
| Intermediate class (III+IV) x Merit: Effort (WE) | 0.296 | |||
| (0.160) | ||||
| Service class (I+II) x Merit: Effort (WE) | -0.046 | |||
| (0.234) | ||||
| Intermediate class (III+IV) x Merit: Talent (WE) | 0.244 | |||
| (0.147) | ||||
| Service class (I+II) x Merit: Talent (WE) | -0.008 | |||
| (0.220) | ||||
| Social Class (Ref.= Working class (V+VI+VII)) x Meritocracy (BE) | ||||
| Intermediate class (III+IV) x Merit: Effort (BE) | 0.572 | |||
| (0.381) | ||||
| Service class (I+II) x Merit: Effort (BE) | 0.299 | |||
| (0.540) | ||||
| Intermediate class (III+IV) x Merit: Talent (BE) | 0.318 | |||
| (0.358) | ||||
| Service class (I+II) x Merit: Talent (BE) | 0.451 | |||
| (0.486) | ||||
| Controls | Yes | Yes | Yes | Yes |
| BIC | 14889.373 | 14890.219 | 14889.362 | 14889.076 |
| Num. obs. | 5755 | 5755 | 5755 | 5755 |
| Groups (idencuesta) | 1027 | 1027 | 1027 | 1027 |
| Variance: idencuesta: (Intercept) | 1.056 | 1.053 | 1.008 | 1.100 |
| Variance: idencuesta: ola_num | 0.025 | 0.025 | 0.024 | 0.024 |
| Variance: idencuesta: merit_effort_dic_cwc | 0.039 | |||
| Variance: idencuesta: merit_talent_dic_cwc | 0.035 | |||
| Variance: idencuesta: merit_effort_dic_mean | 1.535 | |||
| Variance: idencuesta: merit_talent_dic_mean | 1.920 | |||
| Note: Cells contain regression coefficients with standard errors in parentheses. ***p < 0.001; **p < 0.01; *p < 0.05. | ||||
4.10 Interactions meritocracy x time without controls
Show the code
## Interactions merit x time
#m23 <- clmm(just_pension ~ 1 + ola_num + egp + merit_effort_cwc + merit_talent_cwc + merit_effort_mean + #merit_talent_mean + merit_effort_cwc*ola_num + (1 + ola_num| idencuesta),
# link = "logit",
# Hess = TRUE,
# data = df_study1)
#
#m24 <- clmm(just_pension ~ 1 + ola_num + egp + merit_effort_cwc + merit_talent_cwc + merit_effort_mean + #merit_talent_mean + merit_talent_cwc*ola_num + (1 + ola_num | idencuesta),
# link = "logit",
# Hess = TRUE,
# data = df_study1)
#
#
#m25 <- clmm(just_pension ~ 1 + ola_num + egp + merit_effort_cwc + merit_talent_cwc + merit_effort_mean + #merit_talent_mean + merit_effort_mean*ola_num + (1 + ola_num | idencuesta),
# link = "logit",
# Hess = TRUE,
# data = df_study1)
#
#m26 <- clmm(just_pension ~ 1 + ola_num + egp + merit_effort_cwc + merit_talent_cwc + merit_effort_mean + #merit_talent_mean + merit_talent_mean*ola_num + (1 + ola_num | idencuesta),
# link = "logit",
# Hess = TRUE,
# data = df_study1)
#
#save(m23,m24,m25,m26, file = here("output/interactions_merit_time_total.RData"))
load(file = here("output/interactions_merit_time_total.RData"))
ccoef <- list(
"Strongly disagree|Disagree" = "Strongly disagree|Disagree",
"Disagree|Neither agree nor disagree" = "Disagree|Neither agree nor disagree",
"Neither agree nor disagree|Agree" = "Neither agree nor disagree|Agree",
"Agree|Strongly agree" = "Agree|Strongly agree",
merit_effort_cwc = "Merit: Effort (WE)",
merit_talent_cwc = "Merit: Talent (WE)",
merit_effort_mean = "Merit: Effort (BE)",
merit_talent_mean = "Merit: Talent (BE)",
"ola_num:merit_effort_cwc" = "Time x Merit: Effort (WE)",
"ola_num:merit_talent_cwc" = "Time x Merit: Talent (WE)",
"ola_num:merit_effort_mean" = "Time x Merit: Effort (BE)",
"ola_num:merit_talent_mean" = "Time x Merit: Talent (BE)")
texreg::htmlreg(list(m23,m24,m25,m26),
caption.above = T,
caption = NULL,
stars = c(0.05, 0.01, 0.001),
custom.coef.map = ccoef,
digits = 3,
custom.note = "Note: Cells contain regression coefficients with standard errors in parentheses. %stars.",
leading.zero = T,
use.packages = F,
booktabs = F,
scalebox = 0.80,
include.loglik = FALSE,
include.aic = FALSE,
center = T,
custom.gof.rows = list("Controls"=c(rep("No",4))))| Model 1 | Model 2 | Model 3 | Model 4 | |
|---|---|---|---|---|
| Strongly disagree|Disagree | 0.976*** | 0.976*** | 1.588*** | 1.733*** |
| (0.212) | (0.212) | (0.309) | (0.316) | |
| Disagree|Neither agree nor disagree | 3.347*** | 3.347*** | 3.960*** | 4.105*** |
| (0.218) | (0.218) | (0.315) | (0.322) | |
| Neither agree nor disagree|Agree | 4.003*** | 4.003*** | 4.616*** | 4.761*** |
| (0.221) | (0.221) | (0.317) | (0.325) | |
| Agree|Strongly agree | 6.645*** | 6.645*** | 7.254*** | 7.400*** |
| (0.243) | (0.243) | (0.333) | (0.340) | |
| Merit: Effort (WE) | 0.212** | 0.172*** | 0.170*** | 0.173*** |
| (0.077) | (0.041) | (0.041) | (0.041) | |
| Merit: Talent (WE) | 0.038 | 0.032 | 0.038 | 0.034 |
| (0.040) | (0.076) | (0.040) | (0.040) | |
| Merit: Effort (BE) | 0.448*** | 0.449*** | 0.686*** | 0.450*** |
| (0.113) | (0.113) | (0.143) | (0.113) | |
| Merit: Talent (BE) | 0.103 | 0.102 | 0.101 | 0.377** |
| (0.111) | (0.111) | (0.111) | (0.140) | |
| Time x Merit: Effort (WE) | -0.012 | |||
| (0.020) | ||||
| Time x Merit: Talent (WE) | 0.002 | |||
| (0.019) | ||||
| Time x Merit: Effort (BE) | -0.070** | |||
| (0.026) | ||||
| Time x Merit: Talent (BE) | -0.083** | |||
| (0.025) | ||||
| Controls | No | No | No | No |
| BIC | 14807.375 | 14807.753 | 14800.313 | 14797.237 |
| Num. obs. | 5755 | 5755 | 5755 | 5755 |
| Groups (idencuesta) | 1027 | 1027 | 1027 | 1027 |
| Variance: idencuesta: (Intercept) | 0.984 | 0.987 | 0.981 | 0.976 |
| Variance: idencuesta: ola_num | 0.019 | 0.019 | 0.018 | 0.017 |
| Note: Cells contain regression coefficients with standard errors in parentheses. ***p < 0.001; **p < 0.01; *p < 0.05. | ||||
4.11 Interactions meritocracy x time with controls
Show the code
## Interactions merit x time
#m27 <- clmm(just_pension ~ 1 + ola_num + egp + merit_effort_cwc + merit_talent_cwc + merit_effort_mean + #merit_talent_mean + educ + ideo + sex + age + merit_effort_cwc*ola_num + (1 + ola_num| idencuesta),
# link = "logit",
# Hess = TRUE,
# data = df_study1)
#
#m28 <- clmm(just_pension ~ 1 + ola_num + egp + merit_effort_cwc + merit_talent_cwc + merit_effort_mean + #merit_talent_mean + educ + ideo + sex + age + merit_talent_cwc*ola_num + (1 + ola_num | idencuesta),
# link = "logit",
# Hess = TRUE,
# data = df_study1)
#
#
#m29 <- clmm(just_pension ~ 1 + ola_num + egp + merit_effort_cwc + merit_talent_cwc + merit_effort_mean + #merit_talent_mean + educ + ideo + sex + age + merit_effort_mean*ola_num + (1 + ola_num | idencuesta),
# link = "logit",
# Hess = TRUE,
# data = df_study1)
#
#m30 <- clmm(just_pension ~ 1 + ola_num + egp + merit_effort_cwc + merit_talent_cwc + merit_effort_mean + #merit_talent_mean + educ + ideo + sex + age + merit_talent_mean*ola_num + (1 + ola_num | idencuesta),
# link = "logit",
# Hess = TRUE,
# data = df_study1)
#
#save(m27,m28,m29,m30, file = here("output/interactions_merit_time_direct.RData"))
load(file = here("output/interactions_merit_time_direct.RData"))
ccoef <- list(
"Strongly disagree|Disagree" = "Strongly disagree|Disagree",
"Disagree|Neither agree nor disagree" = "Disagree|Neither agree nor disagree",
"Neither agree nor disagree|Agree" = "Neither agree nor disagree|Agree",
"Agree|Strongly agree" = "Agree|Strongly agree",
merit_effort_cwc = "Merit: Effort (WE)",
merit_talent_cwc = "Merit: Talent (WE)",
merit_effort_mean = "Merit: Effort (BE)",
merit_talent_mean = "Merit: Talent (BE)",
"ola_num:merit_effort_cwc" = "Time x Merit: Effort (WE)",
"ola_num:merit_talent_cwc" = "Time x Merit: Talent (WE)",
"ola_num:merit_effort_mean" = "Time x Merit: Effort (BE)",
"ola_num:merit_talent_mean" = "Time x Merit: Talent (BE)")
texreg::htmlreg(list(m27,m28,m29,m30),
caption.above = T,
caption = NULL,
stars = c(0.05, 0.01, 0.001),
custom.coef.map = ccoef,
digits = 3,
custom.note = "Note: Cells contain regression coefficients with standard errors in parentheses. %stars.",
leading.zero = T,
use.packages = F,
booktabs = F,
scalebox = 0.80,
include.loglik = FALSE,
include.aic = FALSE,
center = T,
custom.gof.rows = list("Controls"=c(rep("Yes",4))))| Model 1 | Model 2 | Model 3 | Model 4 | |
|---|---|---|---|---|
| Strongly disagree|Disagree | 0.906*** | 0.909 | 1.393*** | 1.531*** |
| (0.220) | (0.343) | (0.349) | ||
| Disagree|Neither agree nor disagree | 3.171*** | 3.172 | 3.765*** | 3.905*** |
| (0.226) | (0.348) | (0.354) | ||
| Neither agree nor disagree|Agree | 3.813*** | 3.813 | 4.423*** | 4.563*** |
| (0.228) | (0.350) | (0.356) | ||
| Agree|Strongly agree | 6.470*** | 6.471 | 7.066*** | 7.207*** |
| (0.250) | (0.364) | (0.370) | ||
| Merit: Effort (WE) | 0.223** | 0.163 | 0.170*** | 0.172*** |
| (0.075) | (0.041) | (0.041) | ||
| Merit: Talent (WE) | 0.032 | 0.032 | 0.039 | 0.034 |
| (0.040) | (0.040) | (0.040) | ||
| Merit: Effort (BE) | 0.408*** | 0.409 | 0.663*** | 0.426*** |
| (0.093) | (0.141) | (0.110) | ||
| Merit: Talent (BE) | 0.095 | 0.094 | 0.061 | 0.336* |
| (0.091) | (0.108) | (0.137) | ||
| Time x Merit: Effort (WE) | -0.018 | |||
| (0.019) | ||||
| Time x Merit: Talent (WE) | -0.001 | |||
| Time x Merit: Effort (BE) | -0.071** | |||
| (0.026) | ||||
| Time x Merit: Talent (BE) | -0.082** | |||
| (0.025) | ||||
| Controls | Yes | Yes | Yes | Yes |
| BIC | 14900.956 | 14901.875 | 14791.204 | 14788.267 |
| Num. obs. | 5755 | 5755 | 5755 | 5755 |
| Groups (idencuesta) | 1027 | 1027 | 1027 | 1027 |
| Variance: idencuesta: (Intercept) | 0.000 | 0.000 | 0.895 | 0.891 |
| Variance: idencuesta: ola_num | 0.049 | 0.049 | 0.019 | 0.019 |
| Note: Cells contain regression coefficients with standard errors in parentheses. ***p < 0.001; **p < 0.01; *p < 0.05. | ||||